readLines() |
Base R |
Read lines from a text file |
readLines("data/debate.txt") |
str_detect() |
stringr |
Detect pattern matching in strings |
str_detect(line, speaker_pattern) |
str_split_fixed() |
stringr |
Split string into fixed number of pieces |
str_split_fixed(line, ":", 2) |
str_trim() |
stringr |
Remove leading/trailing whitespace |
str_trim(split_line[1]) |
rbind() |
Base R |
Bind rows of data frames together |
rbind(data, data.frame(speaker = current_speaker, text = current_text)) |
skim() |
skimr |
Quick data summary and exploration |
skim(df) |
unique() |
Base R |
Extract unique values |
unique(df$speaker) |
filter() |
dplyr |
Filter rows based on conditions |
filter(speaker == "HARRIS" \| speaker == "TRUMP") |
ifelse() |
Base R |
Vector conditional function |
ifelse(df1$speaker == "HARRIS", "Harris", "Trump") |
unnest_tokens() |
tidytext |
Tokenize text into individual words |
unnest_tokens(word, text) |
anti_join() |
dplyr |
Keep rows not matching another table |
anti_join(stop_words, by = "word") |
count() |
dplyr |
Count occurrences of unique values |
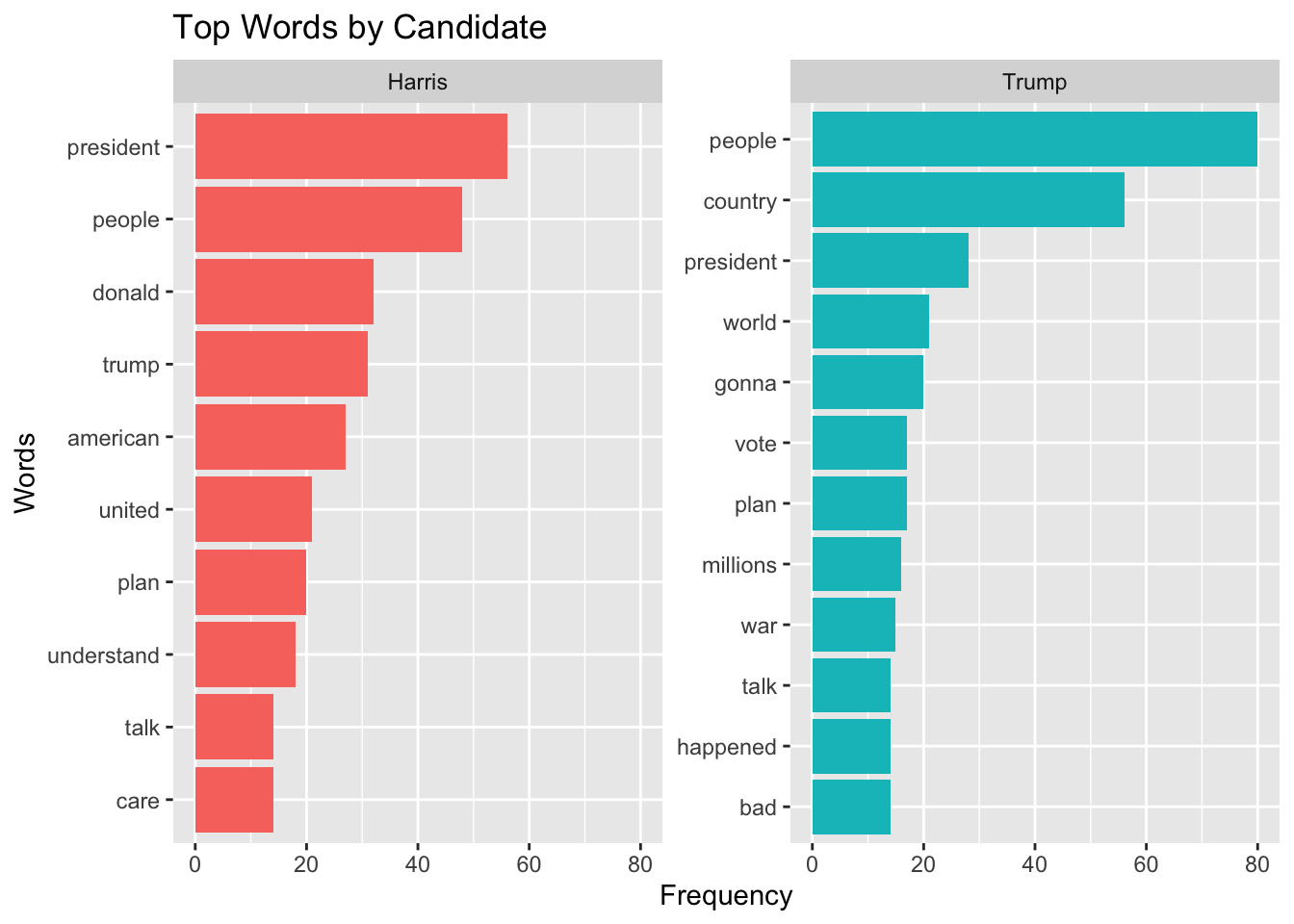
count(speaker, word, sort = TRUE) |
group_by() |
dplyr |
Group data by one or more variables |
group_by(speaker) |
top_n() |
dplyr |
Select top n rows by value |
top_n(10, n) |
ungroup() |
dplyr |
Remove grouping from data frame |
ungroup() |
arrange() |
dplyr |
Sort rows by one or more columns |
arrange(speaker, -n) |
separate() |
tidyr |
Separate a column into multiple columns |
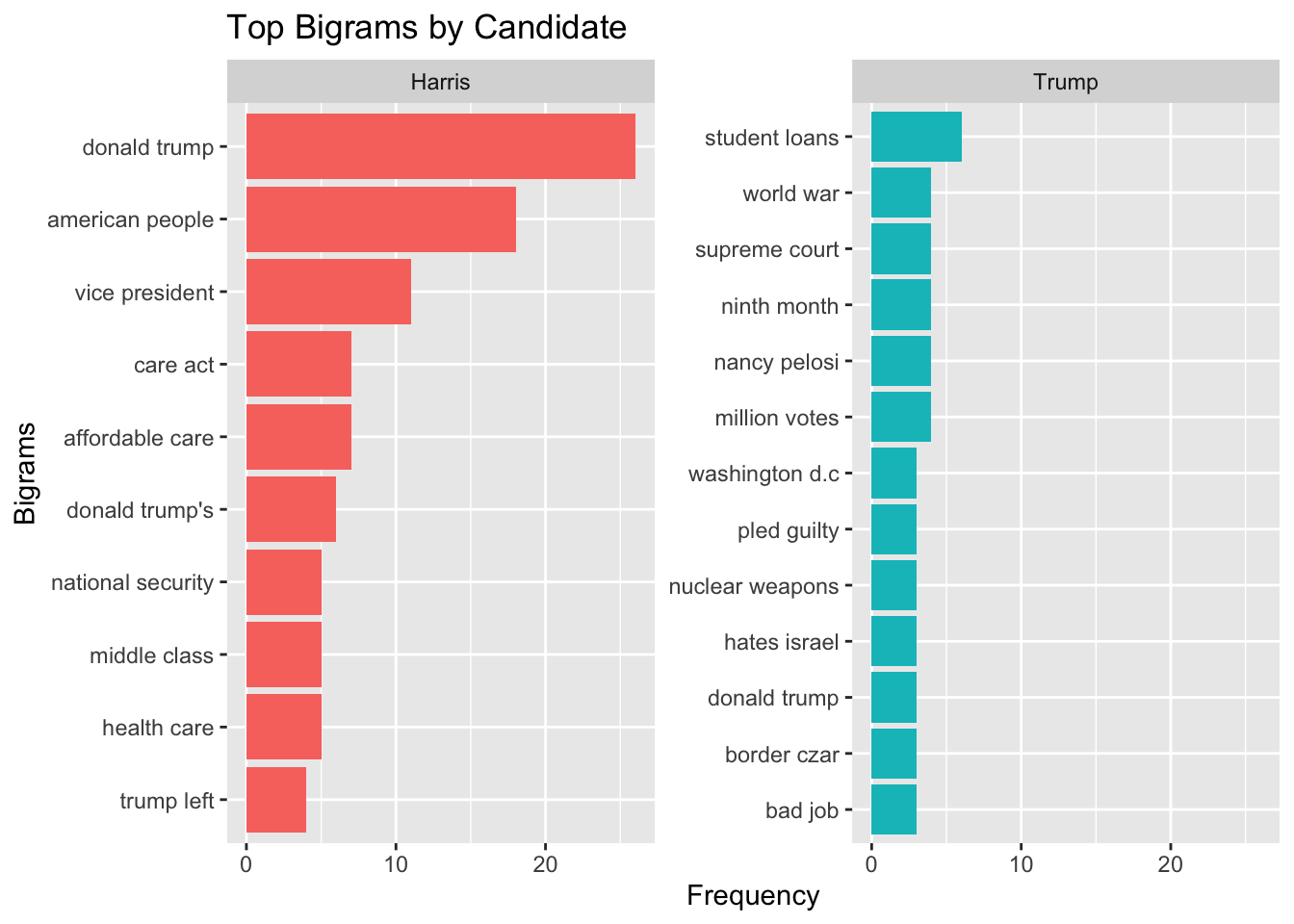
separate(bigram, into = c("word1", "word2"), sep = " ") |
unite() |
tidyr |
Unite multiple columns into one |
unite(bigram, word1, word2, sep = " ") |
mutate() |
dplyr |
Create or modify columns |
mutate(word = tolower(word)) |
tolower() |
Base R |
Convert strings to lowercase |
tolower(word) |
reorder_within() |
tidytext |
Reorder factor within groups for visualization |
reorder_within(word, n, speaker) |
ggplot() |
ggplot2 |
Create a new ggplot object |
ggplot(aes(word, n, fill = speaker)) |
aes() |
ggplot2 |
Specify aesthetic mappings (x, y, color, fill) |
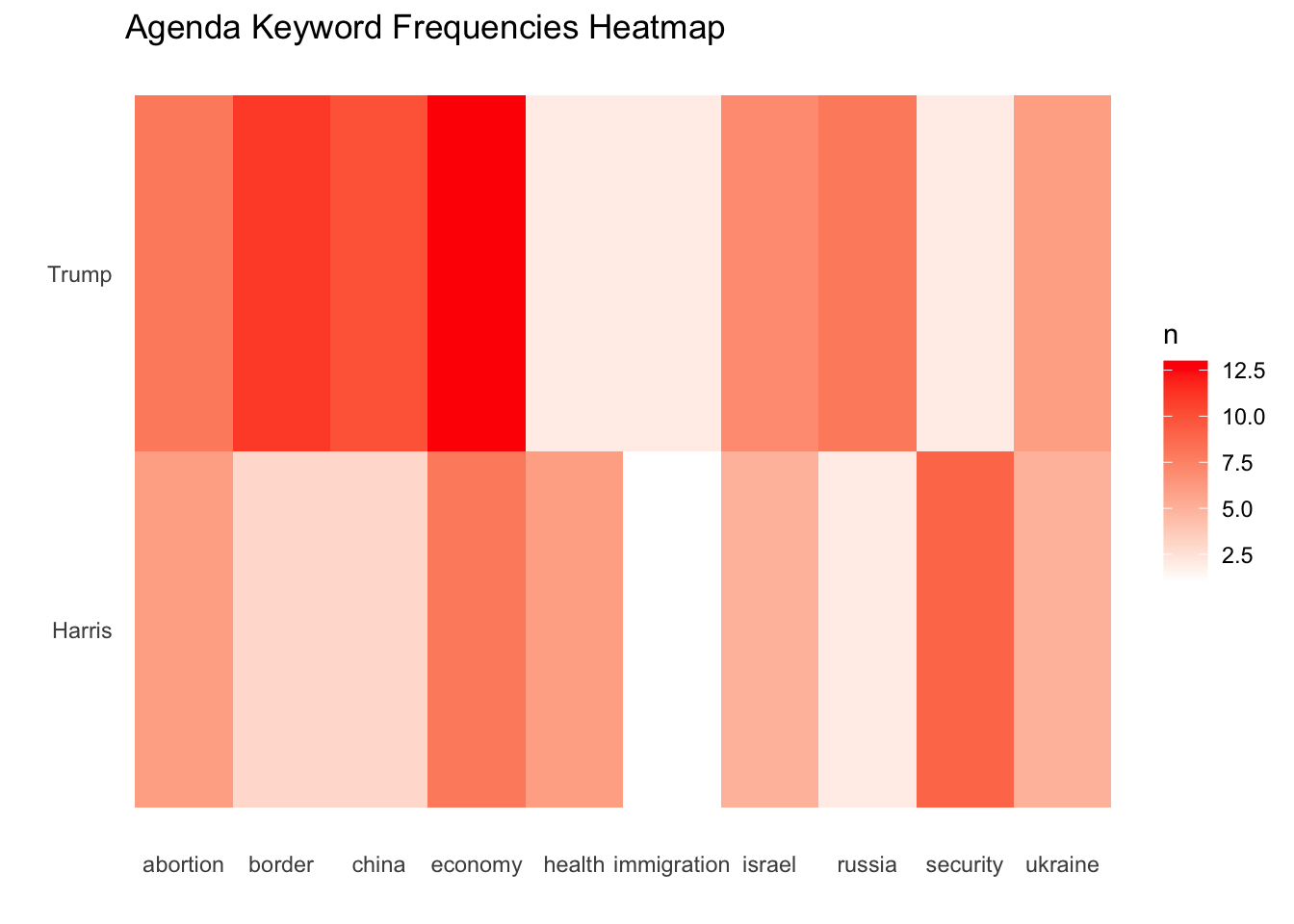
aes(x = word, y = speaker, fill = n) |
geom_col() |
ggplot2 |
Create a bar chart |
geom_col(show.legend = FALSE) |
geom_tile() |
ggplot2 |
Create a heatmap (tile plot) |
geom_tile() |
facet_wrap() |
ggplot2 |
Create multiple plots based on categorical var |
facet_wrap(~speaker, scales = "free_y") |
coord_flip() |
ggplot2 |
Flip x and y axes |
coord_flip() |
scale_x_reordered() |
tidytext |
Apply reordered scale to x-axis |
scale_x_reordered() |
scale_fill_gradient() |
ggplot2 |
Create gradient color scale for fill |
scale_fill_gradient(low = "white", high = "red") |
labs() |
ggplot2 |
Add titles, labels, and captions |
labs(title = "...", x = "Words", y = "Frequency") |
theme_minimal() |
ggplot2 |
Apply minimal theme |
theme_minimal() |
element_blank() |
ggplot2 |
Create blank (invisible) element |
element_blank() |
theme() |
ggplot2 |
Customize plot appearance |
theme(panel.grid.major = element_blank()) |
wordcloud() |
wordcloud |
Create a word cloud visualization |
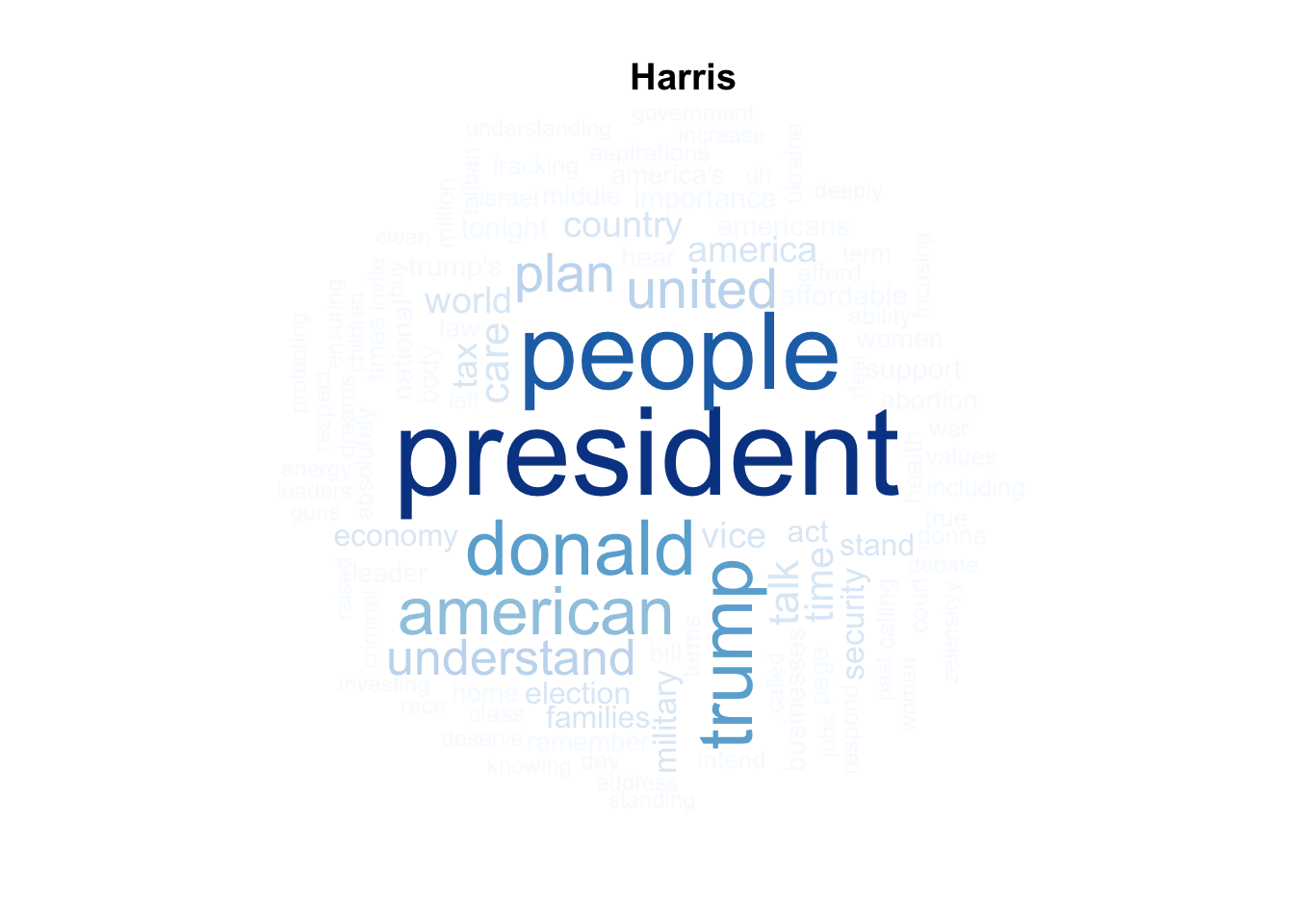
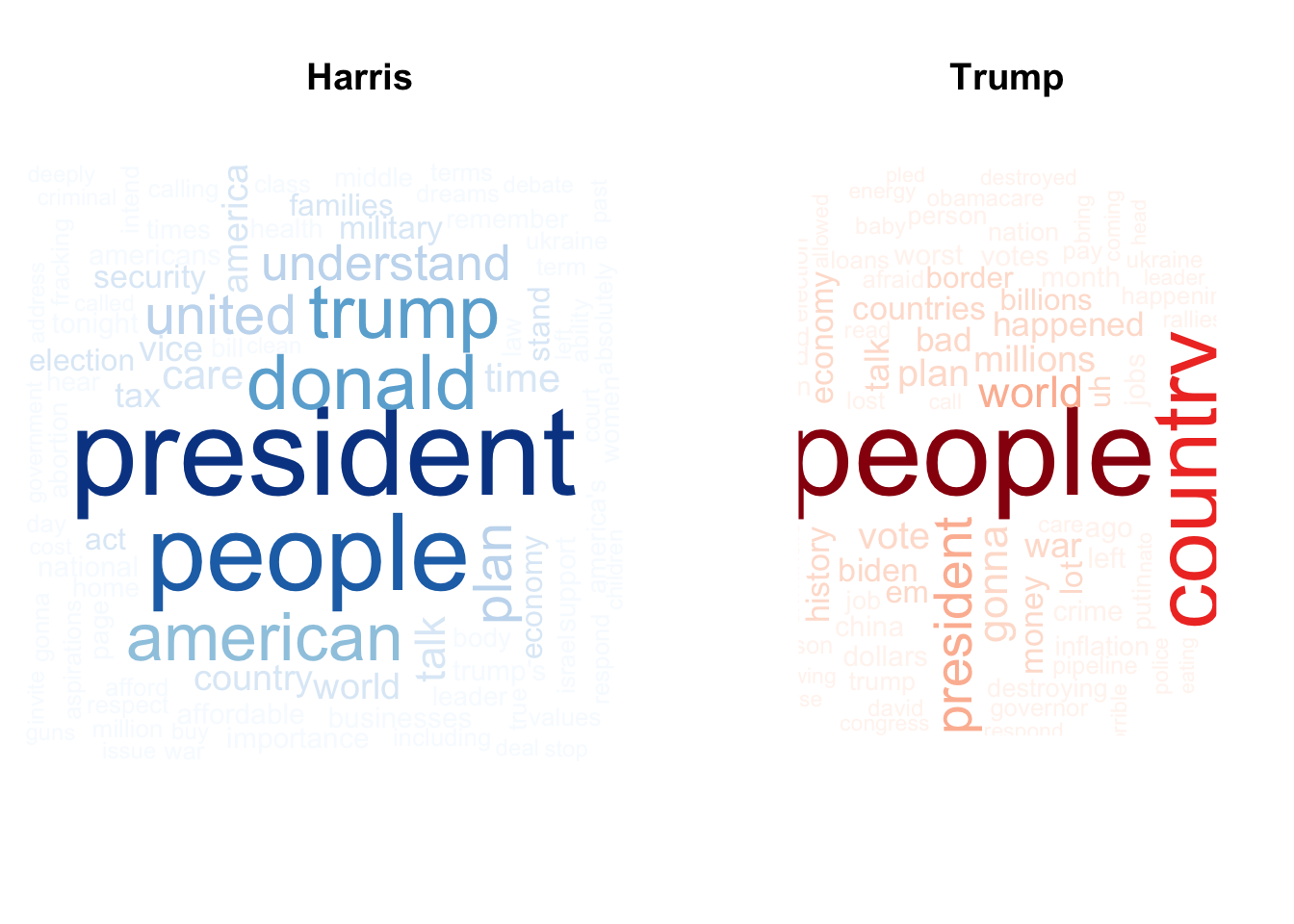
wordcloud(words = harris_words$word, freq = harris_words$n, max.words = 100) |
brewer.pal() |
RColorBrewer |
Generate color palettes |
brewer.pal(8, "Blues") |
par() |
Base R |
Set or query graphical parameters |
par(mfrow = c(1, 2)) |
data() |
Base R |
Load built-in datasets |
data("stop_words") |