In this chapter, we will use a different dataset to demonstrate the three types of questions that are often asked in journalistic reporting.
Building on Previous Chapters
The life expectancy data you learned to transform in the previous chapter (transform-merge.qmd) is now ready for analysis. In this chapter, we’ll take that transformed data and apply analytical techniques to answer journalism questions about global health trends.
Data connection: The life expectancy dataset used here (life_expectancy.csv) can be transformed using the pivot_longer() technique covered in the previous chapter to create the merged dataset (expectancy_merged.RData) that will be used for visualization later.
About the data
This dataset was downloaded from the World Bank website and saved as a CSV file named life_expectancy.csv, stored in the data folder. The dataset was last updated on March 24, 2025, contains the life expectancy at birth for various countries over the years.
Learning Objectives
This chapter will demonstrate three types of data analysis:
Single Variable Analysis: Analyzing the distribution of global life expectancy.
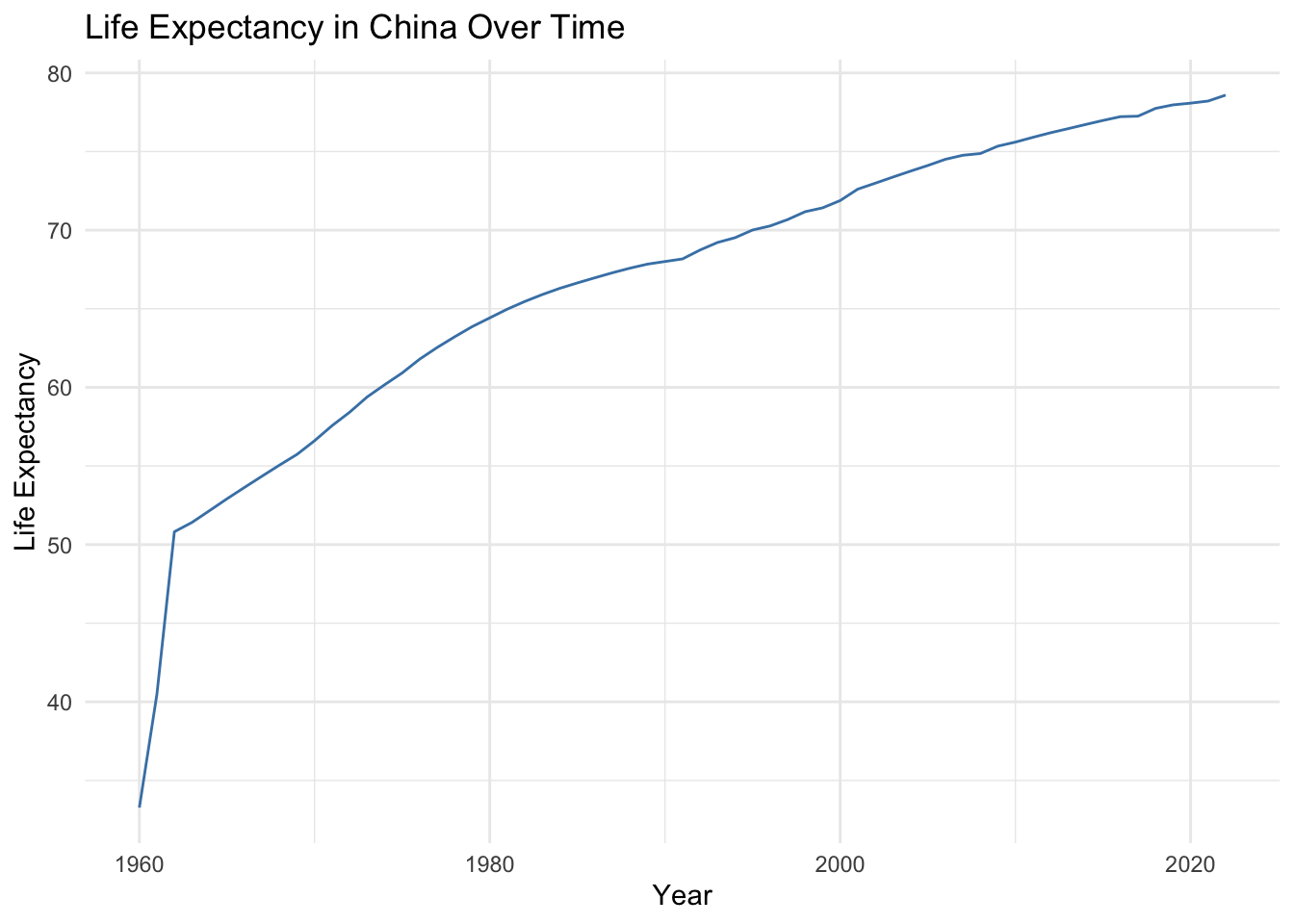
Time-Based Analysis: Tracking changes in China’s life expectancy over time.
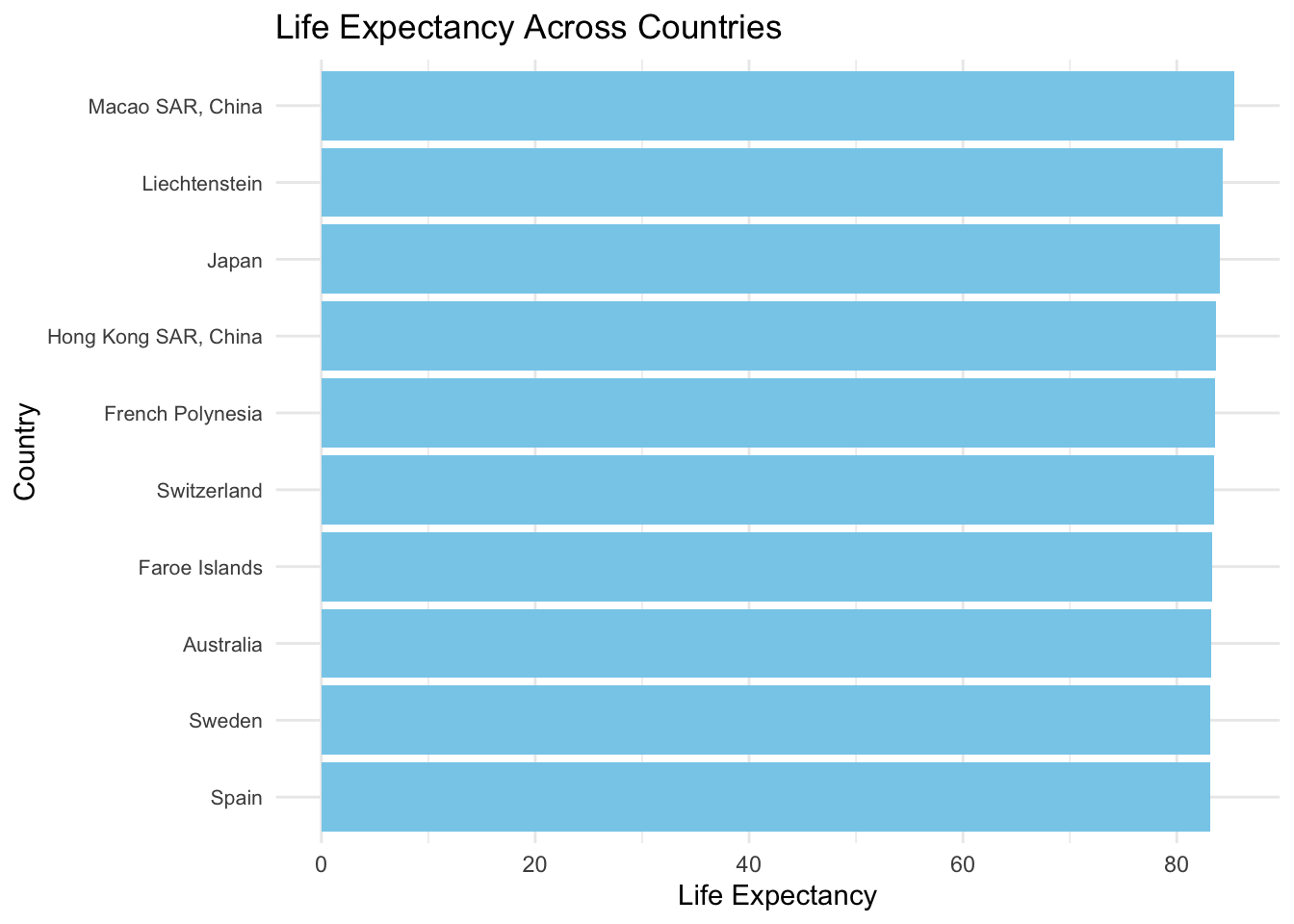
Group Comparisons: Comparing life expectancy across different countries.
7.2 Load data and packages
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.1 ✔ stringr 1.6.0
✔ ggplot2 4.0.0 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.2.0
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
lifex <-read_csv("data/life_expectancy.csv")
New names:
Rows: 266 Columns: 69
── Column specification
──────────────────────────────────────────────────────── Delimiter: "," chr
(4): Country Name, Country Code, Indicator Name, Indicator Code dbl (63): 1960,
1961, 1962, 1963, 1964, 1965, 1966, 1967, 1968, 1969, 1970, ... lgl (2): 2023,
...69
ℹ Use `spec()` to retrieve the full column specification for this data. ℹ
Specify the column types or set `show_col_types = FALSE` to quiet this message.
• `` -> `...69`
7.4 Single Variable Analysis: Understanding Global Life Expectancy Distribution
# Summary statistics of life expectancylifex_clean |>summarise(avg =mean(life_expectancy, na.rm =TRUE),median =median(life_expectancy, na.rm =TRUE),min =min(life_expectancy, na.rm =TRUE),max =max(life_expectancy, na.rm =TRUE) )
# visualize the distribution of life expectancyhist(lifex_clean$life_expectancy, main ="Global Life Expectancy Distribution",xlab ="Life Expectancy",col ="skyblue",border ="black")
7.5 Time-Based Analysis: Tracking Changes in China’s Life Expectancy
lifex_clean |>filter(country =="China") |>ggplot(aes(x = year, y = life_expectancy)) +geom_line(color ="steelblue") +labs(title ="Life Expectancy in China Over Time",x ="Year",y ="Life Expectancy") +theme_minimal()
7.6 Group Comparisons: Comparing Life Expectancy Across Countries